5 Datenanalyse
Nach der Datenerhebung beginnt die Datenanalyse. Die Datenanalyse wird durch die Forschungsfrage und das experimentelle Design determiniert. Die Datenanalyse besteht aus zwei Schritten: Der Aufbereitung der Daten und der Datenanalyse selbst. Die Datenanalyse wiederum besteht aus der deskriptiven Statistik und der Inferenzstatistik. In diesem Kapitel wird jeder dieser Schritte präsentiert. Danach geht das Kapitel darauf ein, wie wichtig die Planung dieser Schritte ist, wie Daten exploriert werden sollen und welche Verhaltensweisen bei der Datenanalyse zu vermeiden sind. Abschliessend geht das Kapitel auf gute Forschungspraxis bei der Datenanalyse ein.
Die deskriptive Statistik wird auch beschreibende Statistik genannt. Die deskriptive Statistik beschreibt die zentralen Tendenzen (z.B. Mittelwert oder Median) und die Streuung (z.B. Standardabweichung und Standardfehler) der erhobenen Daten.
Die Inferenzstatistik wird auch schliessende Statistik genannt. Die Inferenzstatistik bedient sich mathematischer Verfahren, um aufgrund der erhobenen Daten Schlussfolgerungen zur Grundgesamtheit zu machen. Es sollen dabei allgemeingültige Schlussfolgerungen gezogen werden.
Beide Statistiken sind komplementär. Die deskriptive Statistik erlaubt zum Beispiel die Schlussfolgerung, dass die Werte in einer Bedingung kleiner oder grösser sind als in der anderen Bedingung. Ohne die Inferenzstatistik kann aber keine Schlussfolgerung gezogen werden, ob ein solcher Unterschied signifikant und damit bedeutsam ist.
5.1 Datenaufbereitung
Ziel der Datenaufbereitung ist es, «gute» Daten von unvollständigen und nicht repräsentativen Daten zu trennen und die Daten in eine Form zu bringen, damit diese statistisch analysierbar sind. Diese Aufbereitung besteht aus mehreren Schritten:
Die Rohdaten — wie zum Beispiel die Reaktion auf jeden präsentieren Reiz — werden aus der Software zur computergestützten Datenerhebung extrahiert.
Die Rohdaten werden anhand der relevanten Variablen gefiltert. Zum Beispiel werden die Rohdaten aus den Übungsblöcken ausgeschlossen.
Je nach statistischem Verfahren werden die Versuchspersonen mit fehlenden Datenpunkten ausgeschlossen oder die fehlenden Datenpunkte werden mit statistischen Methoden ersetzt.
Je nach statistischen Verfahren werden Ausreisser in den Daten ermittelt und anschliessend entfernt oder ersetzt. Die Suche von Ausreissern kann auf der Ebene der Versuchsperson durchgeführt werden. In dem Fall werden die kompletten Daten einer Ausreisser-Versuchsperson ausgeschlossen. Die Suche nach Ausreissern kann auch auf die Ebene einzelner Durchgänge einer Versuchsperson stattfinden. In dem Fall werden nur die entsprechenden Durchgänge entfernt.
Je nach statistischem Verfahren werden die Daten aggregiert. Für eine Varianzanalyse werden diese zum Beispiel auf der Ebene einzelner Versuchspersonen für jede experimentelle Bedingung gemittelt.
Die aufbereiteten Daten, welche dann für die Datenanalyse verwendet werden, müssen das experimentelle Design reflektieren. Nur so können die Hypothesen getestet werden.
5.2 Datenanalyse
Wenn die Daten aufbereitet sind, wird zuerst die deskriptive Statistik berechnet. Am besten wird dazu eine Abbildung zu den zentralen Tendenzen gemacht. Damit die Abbildung zur Beantwortung der Forschungsfrage beiträgt, muss darauf geachtet werden, dass sie dem experimentellen Design entspricht. Dies bedeutet, dass alle unabhängigen Variablen in der Abbildung dargestellt sein müssen. Hier könnte es hilfreich, zuerst eine Skizze auf Papier anzufertigen, bevor Daten mit der Analysesoftware in eine Abbildung überführt werden.
Im Fall von mehreren abhängigen Variablen empfiehlt es sich, diese in mehreren Teilabbildungen darzustellen. Hier sollte angestrebt werden, die Teilabbildungen so ähnlich wie möglich zu gestalten. Dies vereinfacht den Vergleich der einzelnen Teilabbildungen und somit das Verständnis der Datenlage.
Nach den deskriptiven statistischen Analysen werden die inferenzstatistischen Analysen durchgeführt. Wie die deskriptive Statistik werden die inferenzstatistischen Analysen durch die Forschungsfragen und das experimentelle Design bestimmt. Dabei muss darauf geachtet werden, dass die Voraussetzungen für die Analysen der inferenzstatistischen Verfahren eingehalten werden.
5.3 Planung der Datenanalyse
Die Datenaufbereitung und die Datenanalyse mit der deskriptiven Statistik und der Inferenzstatistik sollte im Voraus gut geplant werden. Zum Beispiel kann jeder Schritt der Datenaufbereitung und der Datenanalyse aufgelistet werden. So kann bei der Realisierung dieser Schritte auf die korrekte Verwendung der Statistiksoftware (wie z.B. R, JAMOVI, JASP oder SPSS) fokussiert werden.
Eine gute Planung soll aber keinesfalls verhindern, dass die Daten bei der Analyse auf unterschiedliche Arten dargestellt werden. Hier sind einige Möglichkeiten aufgelistet:
In einer ersten Abbildung werden die Daten mit einen Balkendiagramm dargestellt. In einer zweiten Abbildung werden sie mit einen Liniendiagramm dargestellt.
In einer ersten Abbildung wird die Bedingung A auf der X-Achse dargestellt und die Bedingung B anhand unterschiedlicher Farben. In einer zweiten Abbildung werden die Bedingungen umgekehrt dargestellt. Die Bedingung A wird somit anhand unterschiedlicher Farben dargestellt und die Bedingung B wird auf der X-Achse dargestellt.
Im Fall von mehr als zwei unabhängigen Variablen werden alle Bedingungen aller Variablen in derselben Abbildung dargestellt. In einer zweiten Variante werden sie über mehrere ähnliche Teilabbildungen dargestellt.
Nachdem die Daten auf unterschiedliche Arten betrachtet wurden, soll die Abbildung ausgewählt werden, welche die Datenlage am besten repräsentiert und die Datenlage nicht verfälscht. Mögliche Fehlinterpretationen sollen zwingend vermieden werden. Eine gute Abbildung hat zwei Eigenschaften:
Das experimentelle Design ist auf einen Blick erkennbar.
Die Daten werden transparent abgebildet. Dies bedeutet, dass die Daten so präsentiert werden, damit diese möglichst einfach interpretiert werden können und falsche Schlüsse vermieden werden (z.B. identische Achsenabschnitte in Abbildungen von verschiedenen Experimenten einer Studie mit vergleichbaren Bedingungen). In dieser Hinsicht ist in der Abbildung 5.1 ein gutes Beispiel und in Abbildung 5.2 ein schlechtes Beispiel dargestellt.
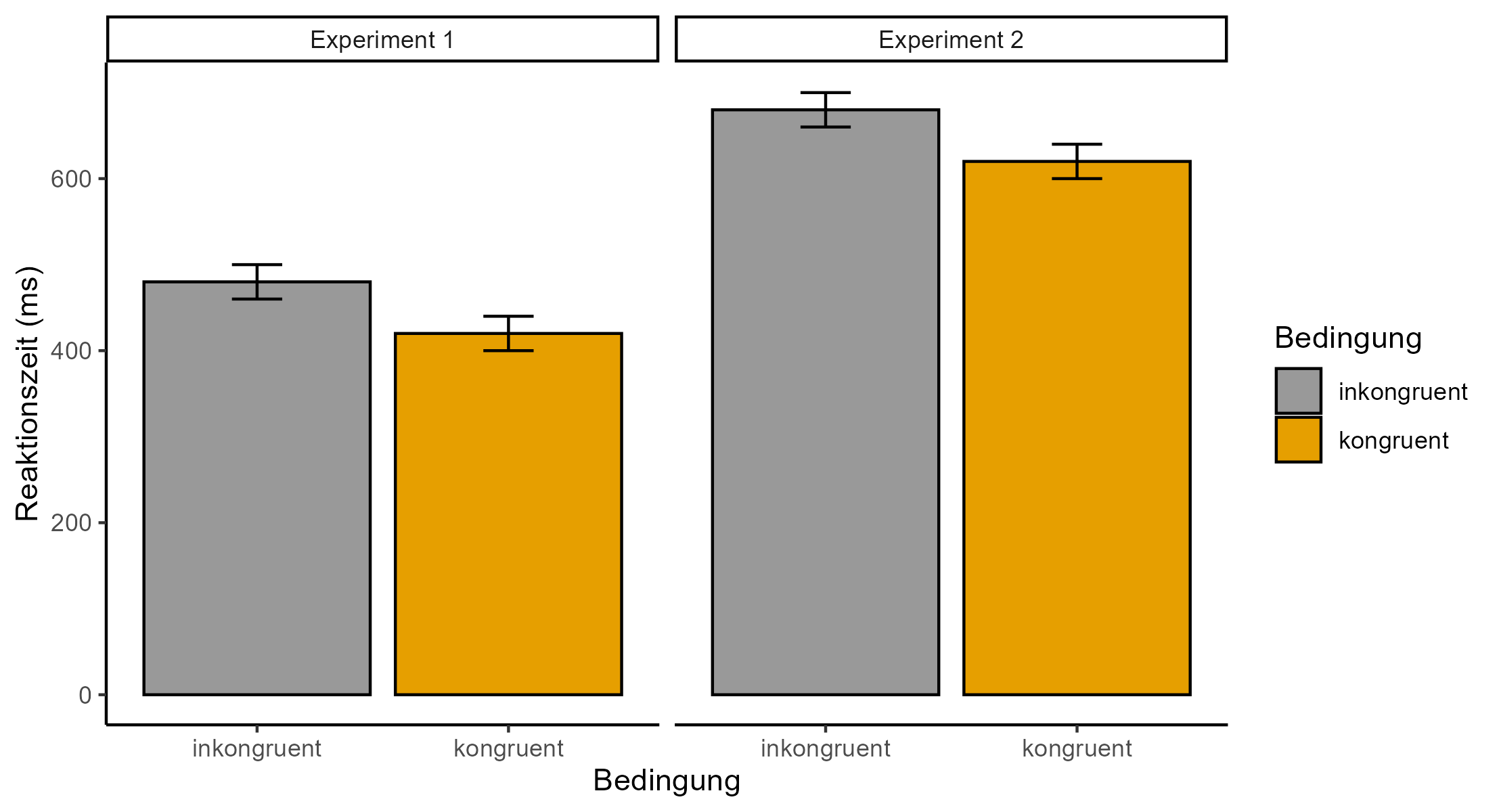
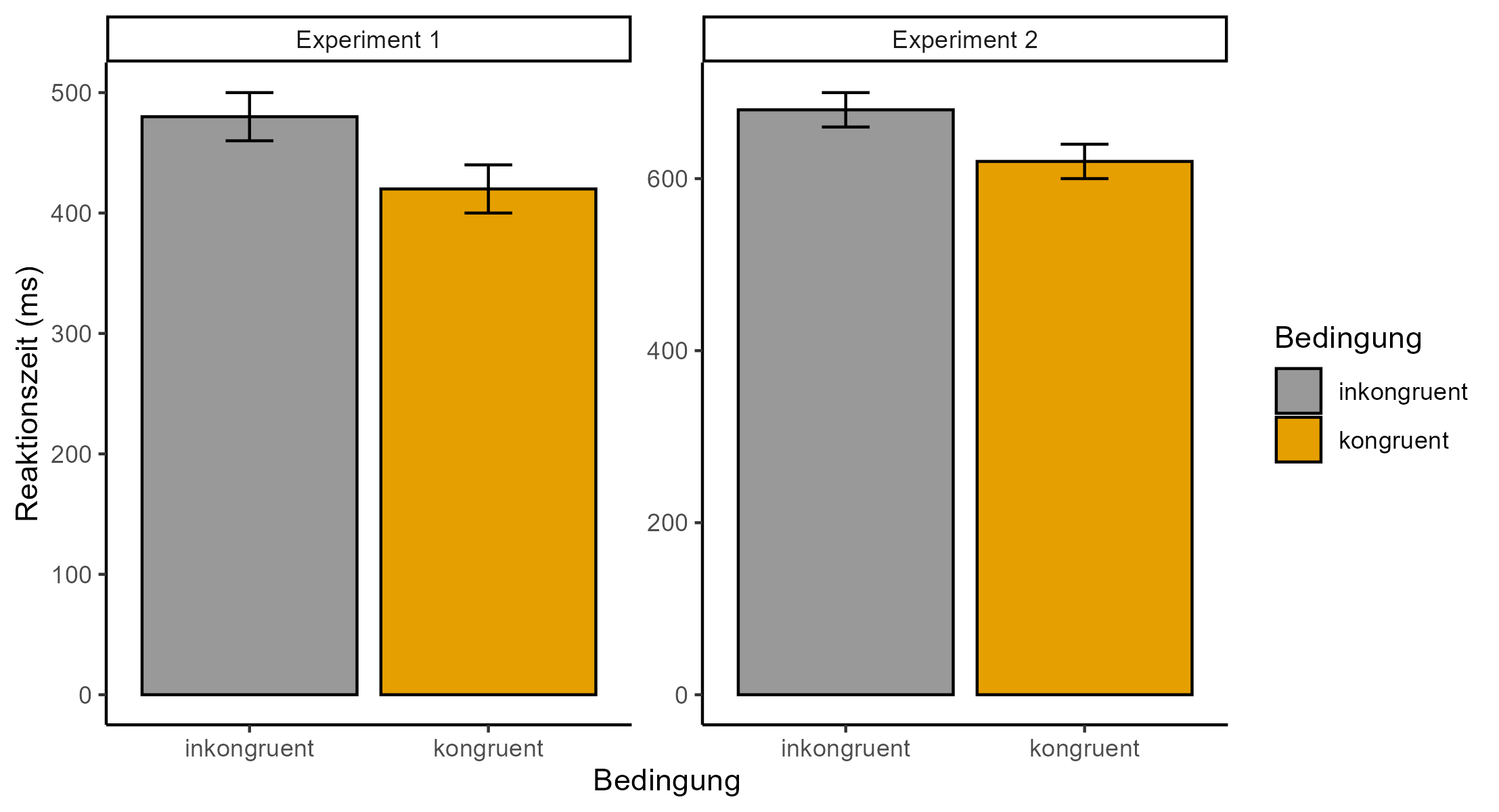
Bei der Datendarstellung sind Abbildungen Tabellen vorzuziehen. Der Grund dafür ist, dass sie das Datenmuster besser erkennen lassen.
Eine geplante Datenanalyse schliesst nicht aus, dass die Daten auch exploriert werden dürfen. Ziel einer explorativen Datenanalyse ist es, die Datenlage besser zu verstehen und mögliche neue bedeutungsvolle Erkenntnisse aufzudecken, welche in zukünftiger Forschung als Hypothesen konfirmativ getestet werden. Auch wenn die Analyse explorativ ist, soll sie sich auf bisherige Befunde im Forschungsgebiet beziehen. Explorative Datenanalysen sollen wie alle Analysen theoriegeleitet begründet werden.
Unabhängig davon, wie die Daten exploriert werden, grundsätzlich wird immer mehr analysiert als am Schluss kommuniziert wird. Wenn aber explorative Analysen berichtet werden, müssen diese als solche ausgewiesen werden. Zum Beispiel kann es geschrieben werden, nachdem die geplanten Analysen abschliessend berichtet wurden: «Mit den Daten wurden folgende explorativen Analysen durchgeführt». Der Leser bzw. die Leserin muss auf Anhieb erkennen können, welche Analysen geplant und somit konfirmatorisch sind und welche Analysen ungeplant und somit explorativ sind.
5.4 Fehlverhalten bei der Datenanalyse
Im Umgang mit Daten sollen bestimmte Verhaltensweisen vermieden werden. Auf zwei davon gehen wir an dieser Stelle näher ein: Die Datenverfälschung und die Datenfälschung. Unter Datenverfälschung fällt das willkürliche Verändern von Daten (z.B. spezifisches und nicht gerechtfertigtes Ausschliessen von Versuchspersonen, um Hypothesen zu bestätigen). Unter Datenfälschung fällt das freie Erfinden / das Fabrizieren von Daten (z.B. Berichten von Mittelwerten, ohne dass jemals Daten erhoben wurden). Beide Vorgehen untergraben die wissenschaftliche Integrität und verursachen enormen Schaden (z.B. Finanzierung von Forschungsprojekten auf Grund unhaltbarer Datenlagen).
Für Studierende können die genannten Verfehlungen die sofortige Exmatrikulation zur Folge haben. Titel, die auf Grund dieser Verfehlungen erworben wurden, können auch noch Jahre nach der ursprünglichen Verfehlung entzogen werden.
Studien, welche auf Grund fehlbarer Verhaltensweisen publiziert wurden, werden öffentlich als solche kenntlich gemacht und «zurückgezogen». Die Namen von Forschern und Forscherinnen können bei entsprechendem fehlbarem Verhalten veröffentlicht werden. Forschern und Forscherinnen können bei entsprechendem fehlbaren Verhalten ihre Stelle verlieren.
5.5 Gute Forschungspraxis
Um diesen Fehlverhalten entgegenzuwirken, wird gute Forschungspraxis seit einigen Jahren in der psychologischen Forschung aktiv stark gefördert (z.B. durch das Center for Open Science). Zentrale Elemente guter Forschungspraxis, insbesondere bei der Datenanalyse, sind Prä-Registrierung, offener Zugang zu Daten und Materialien (engl. Preregistering, Open Data und* Open Materials*, siehe Abbildung 5.3).

Bei der Präregistriereung werden die Theorie, die davon abgeleiteten Hypothesen, Methoden und Datenanalyse vor dem Beginn der Datenerhebung schriftlich festgehalten und mit Zeitstempel «eingefroren», so dass diese nicht im Nachhinein noch verändert werden können. Einmal «eingefroren» kann eine Präregistriereung nicht mehr aus dem Netz entfernt werden. Damit soll verhindert werden, dass die erhobenen Daten so lange mit verschiedenen Parametern (z.B. zum Ausschliessen von Versuchspersonen als Ausreisser) analysiert werden, bis signifikante Ergebnisse gefunden werden, und diese dann so berichtet werden, als hätte man die entsprechende Analyse schon immer so geplant gehabt. Explorative Analysen sind selbstverständlich immer möglich, müssen aber als solche gekennzeichnet werden.
Bei den offenen Daten handelt es sich um das Bereitstellen der Rohdaten auf einem öffentlich zugänglichen Server. Die Daten stehen somit jedermann zur Verfügung (z.B. für Meta-Analysen). Beim Teilen von Daten ist es äussert wichtig, dass jegliche Information, die zur Identifikation von einzelnen Personen führen kann, vor dem Teilen von Daten entfernt wird.
Bei den offenen Materialien (Studienmaterial, Programmcode und Analysecode) handelt es sich das Bereitstellen von Studienmaterialien (z.B. Stimuli), Programmcode (z.B. zur Stimuluspräsentation) und Analysecode (z.B. zur Aufbereitung und Analyse der Daten) auf einem öffentlich zugänglichen Server. Die Studienmaterialien, die Programme für experimentelle Prozeduren sowie die detaillierten Auswertungen stehen somit jedermann zur Verfügung. Allfällige Fehler — inkl. Analysefehler — können im Sinne einer positiven Fehlerkultur entdeckt und korrigiert werden.
Durch das offene Bereitstellen von Materialen und Daten wird der Nutzen von einzelnen Studien erhöht. Oftmals lassen sich die Materialien und die Daten in anderen Studien wieder verwenden.
Das Forschungsprojekt, das im Zeitschriftenartikel zum Zusammenspiel von Tageszeit und Chronotyp und dessen Auswirkungen auf kognitive Leistungen (Rey-Mermet & Rothen, 2023) beschrieben wird, wurde präregistriert. Die Daten sowie die Materialien (Studienmaterialien, Programmcode und Analysecode) wurden auf einem öffentlich zugänglichen Server bereitgestellt.